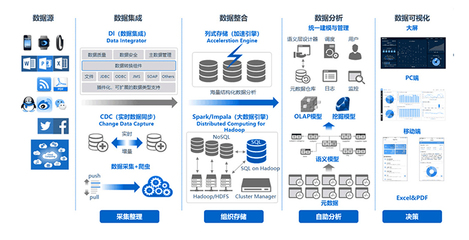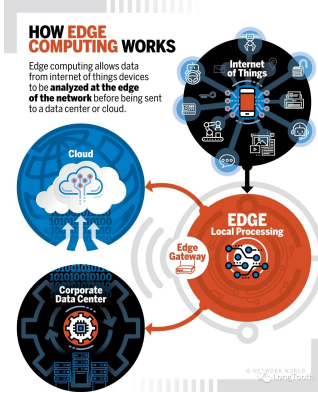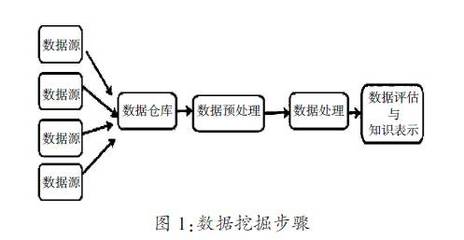
數(shù)據(jù)處理是現(xiàn)代企業(yè)和科研機(jī)構(gòu)面臨的核心任務(wù)之一。隨著數(shù)據(jù)量的爆炸式增長,有效的數(shù)據(jù)處理不僅關(guān)乎業(yè)務(wù)效率,更是決策科學(xué)性的基礎(chǔ)。
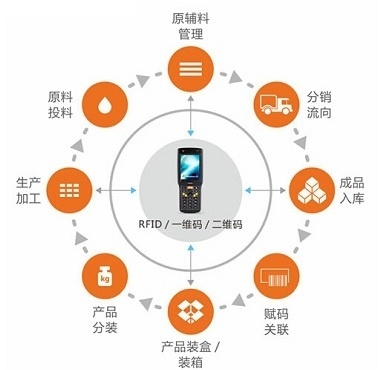
數(shù)據(jù)采集是數(shù)據(jù)處理的基礎(chǔ)。從傳感器、交易記錄到社交媒體,數(shù)據(jù)來源多樣且復(fù)雜。確保數(shù)據(jù)質(zhì)量和一致性是這一階段的關(guān)鍵挑戰(zhàn)。常見的方法包括數(shù)據(jù)清洗、去重和格式標(biāo)準(zhǔn)化,以消除噪聲和異常值。
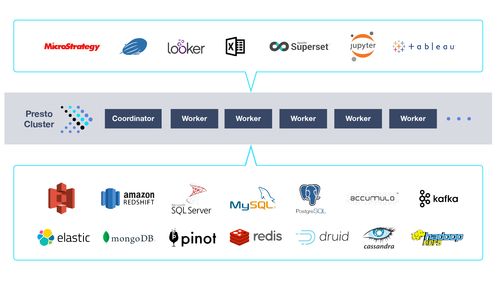
數(shù)據(jù)存儲(chǔ)和管理需要可靠的架構(gòu)。傳統(tǒng)的關(guān)系型數(shù)據(jù)庫與新興的NoSQL系統(tǒng)并存,選擇取決于數(shù)據(jù)類型和查詢需求。云存儲(chǔ)解決方案如AWS S3或Google Cloud Storage提供了可擴(kuò)展性,但需注意數(shù)據(jù)安全和合規(guī)性問題。
接著,數(shù)據(jù)處理本身涉及轉(zhuǎn)換、聚合和分析。ETL(提取、轉(zhuǎn)換、加載)流程是常見手段,而實(shí)時(shí)流處理技術(shù)如Apache Kafka則支持即時(shí)響應(yīng)。機(jī)器學(xué)習(xí)和AI工具的集成進(jìn)一步提升了數(shù)據(jù)價(jià)值提取能力,例如通過Python的Pandas庫進(jìn)行數(shù)據(jù)操作,或使用TensorFlow構(gòu)建預(yù)測模型。
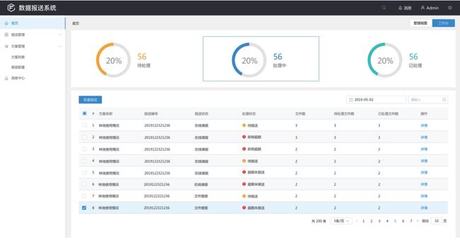
數(shù)據(jù)可視化是最后一步,將處理結(jié)果轉(zhuǎn)化為直觀圖表或儀表板。工具如Tableau或Power BI幫助用戶識(shí)別趨勢,做出數(shù)據(jù)驅(qū)動(dòng)的決策。隱私和倫理問題不容忽視,需遵循GDPR等法規(guī),確保匿名化和權(quán)限控制。
高效的數(shù)據(jù)處理要求整合技術(shù)、工具和流程,同時(shí)關(guān)注安全與合規(guī)。隨著技術(shù)的發(fā)展,自動(dòng)化與智能化將成為未來趨勢,助力組織在數(shù)據(jù)洪流中保持競爭力。